Prometheus와 Python GC 모듈을 이용해 동작중인 애플리케이션의 힙 사용량 측정해 본 이야기
최근에는 애플리케이션들의 관측성을 달성하기 위한 일들을 많이 하고 있다. 모니터링 시스템은 Prometheus 생태계와 Grafana를 이용하고 있다.
Prometheus는 Pulling 방식을 통해 메트릭을 수집하는 오픈소스 TSDB 프로젝트이다.
Prometheus는 메트릭을 수집하기 위한 exporter 라는 수집 에이전트가 있는데,
HTTP 프로토콜이며, 동작이 단순하고, 사용자가 쉽게 exporter를 만들 수 있도록 하는
라이브러리들을 제공하고 있다.
얼마전 파이썬으로 작성된 API 서버가 메모리 릭 현상으로 추정되는 동작을 보여주고 있어서, 해당 문제를 추적하기 위해 파이썬 애플리케이션의 힙 사용량을 실시간으로 측정하기 위한 Prometheus Exporter를 만들어 보고 가시화 한 내용을 공유한다.
사실 위의 사례로 볼 때는 엄밀히는 메모리 누수라고 보기는 힘들고,
불필요하게 메모리를 많이 사용하는 로직을 추적한다는 것이 더 맞는 주제일 것 같다.
메모리 누수
메모리 누수 현상은 간단히 애플리케이션 구동 중에 필요하지 않은 메모리를 계속 점유하고 있는 현상인데, 일반적으로 python 같은 인터프리터 언어 같은 고차원 언어에서는 애플리케이션의 메모리 관리를 위해 Garbage Collection(GC)을 지원한다.
하지만, GC를 지원한다 하더라도 로직의 문제로 애플리케이션이 필요 이상으로 메모리를 많이 점유하게 되는 경우도 있는데, 이 때는 언어 자체에서 지원하는 GC 모듈로는 해결이 불가능한 경우가 많고, 디버깅을 통해서 해결해야 한다.
gc 모듈을 사용해 파이썬 애플리케이션의 heap 사용량 추적
파이썬에서는 파이썬으로 작성된 애플리케이션의 메모리를 관리하기 위해서 GC가 기본적으로 지원되고, 오브젝트의 메모리는 Reference Counting 방법을 통해서 관리하게 된다.
관련해서 사용자(개발자)가 직접 GC 동작에 관여할 수 있도록 gc 모듈을 제공하고 있고, 필요시 gc 모듈을 사용하여, 애플리케이션의 GC 관련 동작을 어느정도 제어할 수 있다.
나는 gc 모듈에서 collect, get_objects, get_referrers 세 함수를 이용해서 애플리케이션이 구동에 필요한 오브젝트들의 메모리 참조관계를 살펴보고, sys 모듈의 getsizeof 함수를 이용해 메모리 사용량을 측정해 보기로 하였다.
- gc.collect(): 애플리케이션에서 GC를 수행한다. 애플리케이션 내에서 비정상적으로 높은 힙 사용량을 추적하기 위해서는 먼저 정리가 필요하다.
- gc.get_objects(): GC에 의해 추적되는 오브젝트들의 리스트가 반환된다. gc.collect() 이후 object 들을 추적해서 해당 오브젝트들을 참조하고 있는 레퍼러들을 추적하기 위해 사용된다.
- gc.get_referrers(*objs):
obj인자로 받아, 입력받은obj를 레퍼런스하고있는 다른 오브젝트들을 추적한다. - sys.getsizeof(type): 특정
type의 메모리 사용량을 알 수 있다.
애플리케이션 내부 Heap 사용량에 대한 Dendrogram 그리기
위 세 함수를 통해서 애플리케이션 내부에 할당된 오브젝트들의 참조 관계들을 엮어서 복잡한 구조를 만들어 낼 수 있었다.
애플리케이션이 간단한 경우는 힙 구조도 단순해서 금방 Dendrogram이 완성되었지만, 다소 복잡한 비즈니스 로직을 처리하는 애플리케이션에서는 힙 구조가 복잡하고 추적해야 할 아이템들이 많으므로, Dendrogram을 구성하는데는 굉장히 오랜 시간이 걸렸다.
실제 환경에서 사용하기 위해 오브젝트 레퍼런스 깊이, 오브젝트의 수, 타입이나 모듈에 대한 필터링 등의 튜닝을 할 수 있도록 해서, 필요한 부분만 추적할 수 있도록 만들어 보았다.
코드에 대한 소개는 너무 장황할 수 있으므로 간단한 흐름만 소개하며, 디테일한 구현은 링크로 대신한다.
- gc.collect() 이후 object들을 조회한다.
- 조회된 object들을 가지고 각 오브젝트의 레퍼러들을 추적한다.
- 레퍼러가 종료 조건에 맞는 경우는 stop.
- 레퍼러들을 풋프린트에 추가하고, 2. 단계로 돌아간다.
종료 조건
- footprint안에 있는지 비교하면서 기존에 카운트된 경우.
- 특정 타입, 또는 모듈에 포함된 객체인 경우.
- 레퍼러들의 깊이가 특정 깊이 이상으로 들어갈 경우.
- 추적한 오브젝트 카운트가 특정 수 이상인 경우.
구현체 링크
Prometheus
CNCF에서 관리되는 오픈소스 모니터링 툴킷이다. 사운드클라우드에서 최초로 작성이 시작되었고 현재는 CNCF의 Gradutated Project로 포지셔닝 되어있다.
자세한 내용은 공식 문서를 참고하면 좋고, 여기서는 Prometheus에 대한 소개는 생략하도록 한다.
Heap Exporter가 노출 할 메트릭 정의
힙 사용량을 측정하기 위해서 세가지 지표를 선정했다.
- heap_size_bytes_total: 트레이싱을 하면서 측정된 전체 힙 사용량 Bytes
- heap_size_bytes: 오브젝트 별 수집된 총 메모리 Bytes
- object_count: python module별 수집된 오브젝트 카운트
Prometheus Exporter를 만들 때는 파이썬 공식 라이브러리를 사용할 수도 있지만, 굳이 그럴 필요 없이 직접 text로 작성해서 노출하기로 하였다.
- 공식 라이브러리가 애플리케이션 설계를 강제하는 부분을 피하고 싶었음.
- Flask 등의 애플리케이션으로 통합 하는데는 공식 라이브러리에서 소개하는 방식은 문제가 있음.
- 이유는 이 문서에서는 생략하기로 한다. (reference)
Prometheus가 읽어들일 수 있는 포맷으로 응답하기만 하면 되므로, 공식 라이브러리는 쓰지 않고 단순하게 처리했다.
테스트
테스트 예제 코드는 링크 참고.
메모리 누수를 발생시키는 애플리케이션 작성
잠재적으로 애플리케이션 상에서 Memory 누수를 일으킬 수 있는
Endpoint를 가진 간단한 Flask 애플리케이션을 작성해 보았다.
# file: app.py
from flask import Flask
# 이번 문서에서 작성한 모듈을 로드한다.
from heapsy import HeapDendrogram
class LeakObj(object):
data = 1
app = Flask(__name__)
leakable = []
@app.route('/leakable')
def leak():
# API 요청이 들어올 때 마다 global에 정의된 leackable 리스트에
# LeakObj 인스턴스가 쌓이게 된다.
global leakable
leakable.append(LeakObj())
return f'hi {len(leakable)}'
@app.route('/metrics')
def heap_usage():
# 힙을 사용량을 추적하기 위한 prometheus metric endpoint를 추가한다.
hd = HeapDendrogram()
hd.generate()
return hd.as_prometheus_metric()
if __name__ == '__main__':
# localhost:5000 에서 listen
app.run()
작성한 애플리케이션을 동작시킨다.
python app.py
Prometheus에 scrape 설정 추가
Prometheus에 테스트 할 API서버를 target으로 추가한다. Prometheus 서비스는 로컬환경에서 docker-compose를 이용해 구동하도록 설정한다.
# file: prometheus.yml
scrape_configs:
- job_name: 'flask-heapusage'
scrape_interval: 30s
scrape_timeout: 30s
static_configs:
- targets:
- localhost:5000
docker-compose를 이용해 간단한 서비스 스택 정의
# file: docker-compose.yml
version: '3'
services:
prometheus:
image: prom/prometheus
network_mode: host
volumes:
- ./prometheus.yml:/etc/prometheus/prometheus.yml
Prometheus 기동
docker-compose up -d
API 요청을 주기적으로 발생시키면서 힙 사용량 추적하기
watch 를 이용해 작성한 API로 요청을 계속 보내도록 한다.
# 0.1초마다 해당 API로 요청을 보내게 된다.
watch -n .1 'curl localhost:5000/leakable'
...
Every 0.1s: curl localhost:5000/leakable ashon-laptop: Tue Aug 25 01:31:08 2020
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
0 0 0 0 0 0 0 0 --:--:-- --:--:-- --:--:-- 0 100 7 100
7 0 0 70 0 --:--:-- --:--:-- --:--:-- 70
hi 8478
Prometheus에 object_count 메트릭을 쿼리해 보자.
PromQL: object_count
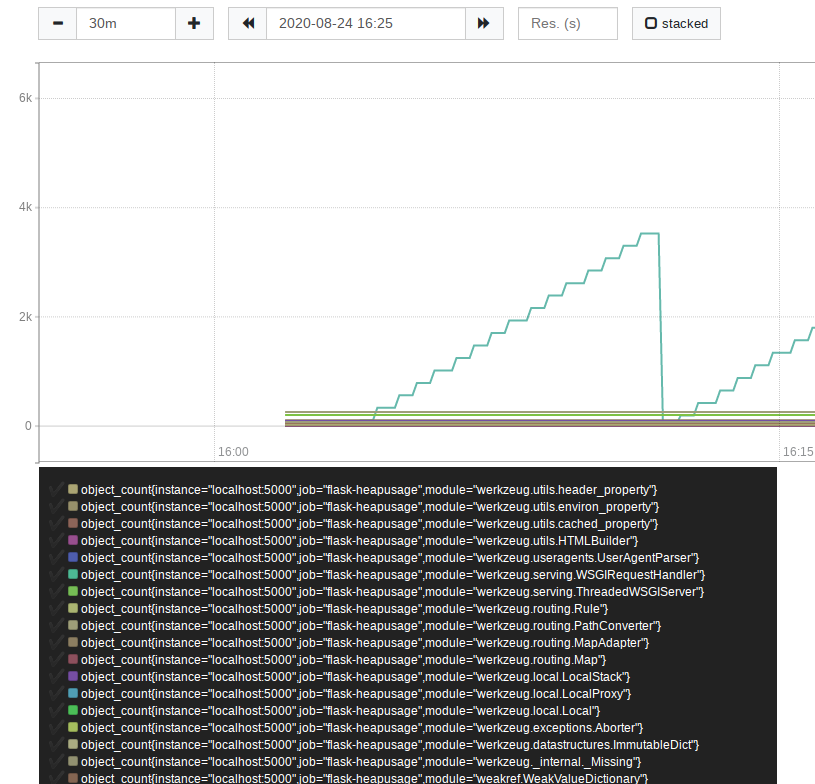
쿼리 결과를 보면, 특정 오브젝트가 증가하는 모습을 확인할 수 있다. 해당 오브젝트를 추적하기 위해 좀더 디테일한 쿼리를 해 보자.
PromQL: object_count{module=~"__main__.*"}
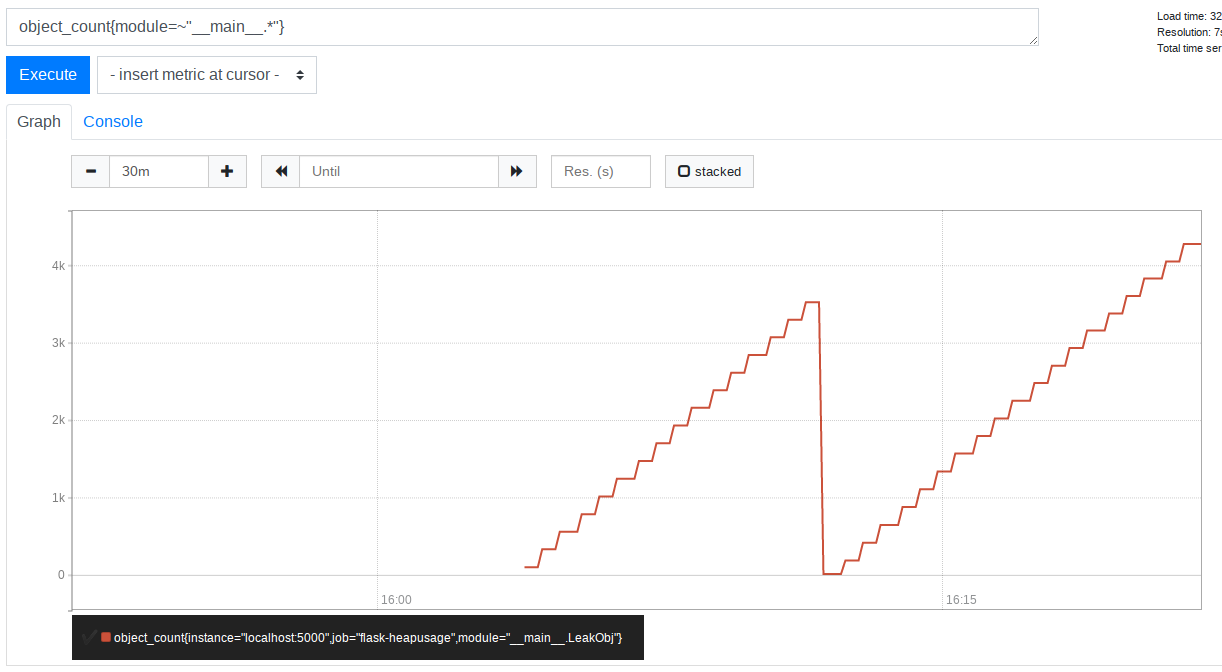
__main__.LeakObj 오브젝트가 시간에 따라 계속 증가함을 확인할 수 있다.
API가 메모리 누수가 있을 때 발견할 수 있는 전형적인 Sawtooth 패턴이다.
측정을 진행하다가 앱을 재시작해서 오브젝트 카운트가 도중에 0으로 떨어졌다.
해당 문서에서는 예제로 설명을 하였는데, 실제 사례에서도 이런 패턴들을 찾아낼 수 있고, 해당 오브젝트가 사용되는 부분을 찾아서 애플리케이션 로직을 튜닝하는 데 사용할 수 있었다.
결론
Prometheus 에코시스템을 이용해서 동작중인 애플리케이션의 힙 사용량을 Exporter 형태로 만들어 보면서, 애플리케이션 내부에서 내가 그동안 알지 못했던 많은 오브젝트들이 복잡한 구조로 동작하고 있음을 알 수 있었다.
힙 사용량 만으로 애플리케이션의 성능이나 가용성을 측정할 수는 없겠지만, 적어도 프로세스 레벨의 메모리 사용량만으로는 추적하기 힘든 부분들까지 찾아내서 수정할 수 있는 방법을 알게되었다.
새삼 예제코드와 글을 같이 쓰시는 분들을 보며 대단하다는 생각이 든다.